Formalization[]
Mapping where are name mentions, characterized by name m.S, context m.C and document m.D and are entities in a knowledge base.[1]



Approaches[]
Individual[]
This approach assumes that the disambiguation of different mentions are independent. It solves the optimization problem:

where measure the compatibility between the mention and the entity chosen by .



Features used in this approach may come from surrounding words, sentence or paragraph (e.g. DBpedia Spotlight).
- Bag of Words (BoW), cosine similarity: Mihalcea & Csomai[2]
- BoW + Categories: Cucerzan (2007)[3], Bunescu & Pasca[4], Fader et al.[5]
Some employed algorithms:
- Classification: Zhang et al.[6] and Mihalcea & Csomai[2].
- Learning-to-rank techniques: Zheng et al.[7], Dredze et al.[8] and Zhou et al.[9]
TODO: a survey: http://www.jair.org/media/4129/live-4129-7870-jair.pdf
Relational heuristics[]
The idea was that the referent entity of a name mention should be coherent with its unambiguous contextual entities.
- Medelyan et al.[10] determined the compatibility using the semantic relatedness between the candidate entity and the contextual entities.
- Milne and Witten[11] extended the method of Medelyan et al. by adopting learning-based techniques to balance the semantic relatedness, the commonness and the context quality.
Collective[]
- Main article: Collective named entity disambiguation
Some algorithms disambiguate based on collective topic coherence only, for example BabelFy[12].
Individual+Collective[]
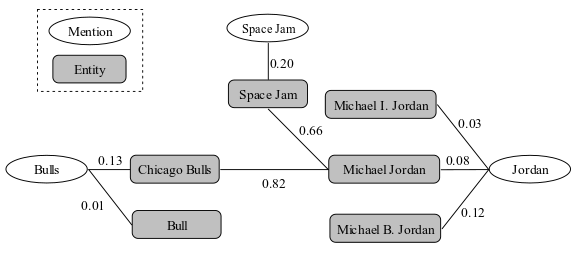
An example of referent graph from Han et al. (2011)[1]
Collective approaches combine local information with global inference to achieve better results. Given a coherence function that assigns a number for each assignment of the whole document, the optimization goal is now:

![{\displaystyle \Gamma _{local}^{*}=\arg \max _{\Gamma }\left[\sum _{i=1}^{k}\phi (m_{i},\gamma _{i})\right]+\psi (\Gamma )}](https://services.fandom.com/mathoid-facade/v1/media/math/render/svg/6d0c042dd16a0d335aed1246ce047a7b7190b3d9)
For some choices of coherence function, the problem has been proved to be NP-Hard.[13]
Some references:
- Pair-wise interdependence: Kulkarni et al.[13].
- Directly connected entities: Han et al.[1], Hoffart et al. (2011)[14]
- All semantically related entities: Guo & Barbosa (2014)[15]
Reranking[]
- Language model: Dalvi et al. (2014)[16](doesn't fit neatly in individual-collective spectrum?)
Features[]
Local features[]
Probability of context[]
Encodes the context of the named entities, i.e. , where c is context of the named entity e. For a specific context, a higher probability will be assigned to the named entity which frequently appears with that context. Han and Sun (2011)[17] proposed an entity context model to estimate the distribution by encoding the context of an entity e in a unigram language model. They define the context as the surrounding window of 50 terms, and used this formula to find the entity context probability:


where , and is the frequency of occurrence of term t in the context of the named entity e.


{kind=link}
Evaluation[]
Datasets[]
- Wikipedia articles: traditionally used but Kulkarni et al. (2009)[13] pointed out that it is unsuitable to the evaluation of high-recall entity linking tasks because it annotates name mentions very sparsely (only the important name mentions are annotated).
- TAC 2009[18]: focuses on individual EL tasks in different documents, unsuitable for our collective EL settings.
- IITB dataset[13]: a set of documents (107 documents in total) collected from the web sites belonging to a handful of domains. For each document, its name mentions’ referent entities in Wikipedia are manually annotated to be as exhaustive as possible. In total, 17,200 name mentions are annotated, 161 name mentions per document on average.
- KORE50 (Hoffart et al., 2012)[19], which consists of 50 short English sentences (mean length of 14 words) with a total number of 144 mentions manually annotated using YAGO2, for which a Wikipedia mapping is available. This dataset was built with the idea of testing against a high level of ambiguity for the EL task.
- AIDA-CoNLL (Hoffart et al., 2011)[20], which consists of 1392 English articles, for a total of roughly 35K named entity mentions annotated with YAGO concepts separated in development, training and test sets.
Evaluation criteria[]
- F-score
Application[]
- Information extraction
- Knowledge base population
- Semantic search
See also[]
References[]
- ↑ 1.0 1.1 1.2 Han, X., Sun, L., & Zhao, J. (2011, July). Collective entity linking in web text: a graph-based method. In Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval (pp. 765-774). ACM.
- ↑ 2.0 2.1 Mihalcea, R. & Csomai, A. 2007. Wikify!: linking documents to encyclopedic knowledge. In: Proceedings of the sixteenth ACM CIKM.
- ↑ Cucerzan, S. 2007. Large-scale named entity disambiguation based on Wikipedia data. In: Proceedings of EMNLP-CoNLL.
- ↑ Bunescu, R. & Pasca, M. 2006. Using encyclopedic knowledge for named entity disambiguation. In: Proceedings of EACL, vol. 6.
- ↑ Fader, A., Soderland, S., Etzioni, O. & Center, T. 2009. Scaling Wikipedia-based named entity disambiguation to arbitrary web text. In: Proceedings of Wiki-AI at IJCAI.
- ↑ Zhang, W., Su, J., Tan, Chew Lim & Wang, W. T. 2010. Entity Linking Leveraging Automatically Generated Annotation. In: Proceedings of the 23rd COLING.
- ↑ Zheng, Z., Li, F., Huang, M. & Zhu, X. 2010. Learning to Link Entities with Knowledge Base. In: The Proceedings of NAACL.
- ↑ Dredze, M., McNamee, P., Rao, D., Gerber, A. & Finin, T. 2010. Entity Disambiguation for Knowledge Base Population. In: Proceedings of COLING.
- ↑ Zhou, Y., Nie, L., Rouhani-Kalleh, O., Vasile, F. & Gaffney, S. 2010. Resolving Surface Forms to Wikipedia Topics. In: Proceedings of the 23rd COLING.
- ↑ Medelyan, O., Witten, I. H. & Milne, D. 2008. Topic indexing with Wikipedia. In: Proceedings of the AAAI WikiAI workshop.
- ↑ Milne, D. & Witten, I. H. 2008. Learning to link with Wikipedia. In: Proceedings of the 17th ACM CIKM.
- ↑ Moro, A., Raganato, A., & Navigli, R. (2014). Entity Linking meets Word Sense Disambiguation: A Unified Approach. Transactions of the Association for Computational Linguistics, 2, 231–244. Retrieved from http://www.transacl.org/wp-content/uploads/2014/05/54.pdf
- ↑ 13.0 13.1 13.2 13.3 Kulkarni, S., Singh, A., Ramakrishnan, G. & Chakrabarti, S. 2009. Collective annotation of Wikipedia entities in web text. In: Proceedings of the 15th ACM SIGKDD
- ↑ Hoffart, J., Yosef, M. A., Bordino, I., Fürstenau, H., Pinkal, M., Spaniol, M., ... & Weikum, G. (2011, July). Robust disambiguation of named entities in text. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (pp. 782-792). Association for Computational Linguistics.
- ↑ Guo, Z., & Barbosa, D. (2014, April). Entity linking with a unified semantic representation. In Proceedings of the companion publication of the 23rd international conference on World wide web companion (pp. 1305-1310). International World Wide Web Conferences Steering Committee.
- ↑ Dalvi, B., Xiong, C., & Callan, J. (2014, July). A language modeling approach to entity recognition and disambiguation for search queries. In Proceedings of the first international workshop on Entity recognition & disambiguation (pp. 45-54). ACM.
- ↑ Xianpei Han and Le Sun. A generative entity-mention model for linking entities with knowledge base. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1, pages 945–954. Association for Computational Linguistics, 2011.
- ↑ McNamee, P. & Dang, H. T. 2009. Overview of the TAC 2009 Knowledge Base Population Track. In: Proceeding of Text Analysis Conference.
- ↑ Johannes Hoffart, Stephan Seufert, Dat Ba Nguyen, Martin Theobald, and Gerhard Weikum. 2012. KORE: keyphrase overlap relatedness for entity disambiguation. In Proc. of CIKM, pages 545–554.
- ↑ Johannes Hoffart, Mohamed Amir Yosef, Ilaria Bordino, Hagen Furstenau, Manfred Pinkal, Marc Spaniol, Bilyana Taneva, Stefan Thater, and Gerhard Weikum. 2011. Robust disambiguation of named entities in text. In Proc. of EMNLP, pages 782–792.