(Paccanaro&Hilton(2000)) Tag: Visual edit |
Tag: Visual edit |
||
| Line 9: | Line 9: | ||
== Approaches == |
== Approaches == |
||
| − | === |
+ | === Proposition completion === |
[[File:Hilton 1986 - tranined weights.png|thumb|220x220px|From Hilton (1986): White rectangles stand for positive weights, black for negative weights, and the area of a rectangle encodes the magnitude of its weight. The two isomorphic family trees are represented in two rows, aligned to equivalent members.]] |
[[File:Hilton 1986 - tranined weights.png|thumb|220x220px|From Hilton (1986): White rectangles stand for positive weights, black for negative weights, and the area of a rectangle encodes the magnitude of its weight. The two isomorphic family trees are represented in two rows, aligned to equivalent members.]] |
||
Hilton (1986) had his neural network learn two family trees and got interesting representations of family members as a by product. The trees were turned in to 104 propositions (''person1'', ''relation'', ''person2'') of which 100 were used for training. For each proposition, the neural network was given fillers of two first roles and asked to predict that of the third. |
Hilton (1986) had his neural network learn two family trees and got interesting representations of family members as a by product. The trees were turned in to 104 propositions (''person1'', ''relation'', ''person2'') of which 100 were used for training. For each proposition, the neural network was given fillers of two first roles and asked to predict that of the third. |
||
| Line 20: | Line 20: | ||
and relations from positive and negative propositions. In ''Neural Networks, 2000. IJCNN 2000, Proceedings of the IEEE-INNS-ENNS International Joint Conference on'' (Vol. 2, pp. 259-264). IEEE.</ref> extended the model to handle special cases where there is no answer or are multiple answers. |
and relations from positive and negative propositions. In ''Neural Networks, 2000. IJCNN 2000, Proceedings of the IEEE-INNS-ENNS International Joint Conference on'' (Vol. 2, pp. 259-264). IEEE.</ref> extended the model to handle special cases where there is no answer or are multiple answers. |
||
| − | === |
+ | === Proposition judgement === |
[[File:Socher's neural network for reasoning.png|thumb|329x329px|From Socher et al. 2013]] |
[[File:Socher's neural network for reasoning.png|thumb|329x329px|From Socher et al. 2013]] |
||
| + | === Relation predicting === |
||
| ⚫ | |||
| + | Bowman (2013)<ref>Bowman, S. R. (2013). Can recursive neural tensor networks learn logical reasoning?. ''arXiv preprint arXiv:1312.6192''.</ref> employed a neural network with one hidden layer and one softmax layer to predict the relation (one of entailment, reverse entailment, equivalent, alternation, negation, cover, and independent) between two phrases. |
||
| ⚫ | |||
Beltagy et al. (2013)<ref>Beltagy, I., Chau, C., Boleda, G., Garrette, D., & Erk, K. (2013). Montague Meets Markov : Deep Semantics with Probabilistic Logical Form. ''Proceedings of the Second Joint Conference on Lexical and Computational Semantics (*Sem-2013)'', 11–21.</ref> performed [[textual entailment recognization]] and [[semantic textual similarity]] by casting them as probabilistic entailment in [[Markov logic]]. For example, the similarity between two sentences: |
Beltagy et al. (2013)<ref>Beltagy, I., Chau, C., Boleda, G., Garrette, D., & Erk, K. (2013). Montague Meets Markov : Deep Semantics with Probabilistic Logical Form. ''Proceedings of the Second Joint Conference on Lexical and Computational Semantics (*Sem-2013)'', 11–21.</ref> performed [[textual entailment recognization]] and [[semantic textual similarity]] by casting them as probabilistic entailment in [[Markov logic]]. For example, the similarity between two sentences: |
||
| Line 29: | Line 31: | ||
S2: A man is slicing a zucchini. |
S2: A man is slicing a zucchini. |
||
| − | is judged as judged as the average degree of mutual entailment (<math>S_1 \models S_2</math> and <math>S_2 \models S_1</math>). |
+ | is judged as judged as the average degree of mutual entailment (<math>S_1 \models S_2</math> and <math>S_2 \models S_1</math>). Strictly speaking, S1 does not entail S2 and vice versa. The authors fixed this by adding the rule cucumber(x)→zucchini(x) | wt(cuc., zuc.) which literally means "if something is a cucumber, it is also a zucchini" (with inference cost=wt(...)). wt(.) is a function of the cosine similarity between two words. |
| − | |||
| − | which literally means "if something is a cucumber, it is also a zucchini" (inference cost=wt(...)) |
||
== References == |
== References == |
||
<references /> |
<references /> |
||
Revision as of 14:56, 30 October 2014
With the wave of deep learning, researchers paid more and more attention to distributed representation. Although successful in many tasks, it has always been know that this approach has serious drawbacks that are strength of logic such as compositionality. Therefore the interest in combining them has also raised significantly.
We may frame this line of research in a larger topic combining symbolic and sub-symbolic approaches which was fashionable during 1980s-1990s (e.g. Hilton, 1986[1]; Ultsch, 1994[2], 1995[3]). However the aim of recent research has contracted and terminology has been much distilled.
Different models have been proposed to solve different specific tasks such as knowledge base completion (Socher et al. 2013[4]), small-scale reasoning (Rocktäschel 2014[5]).
Approaches
Proposition completion
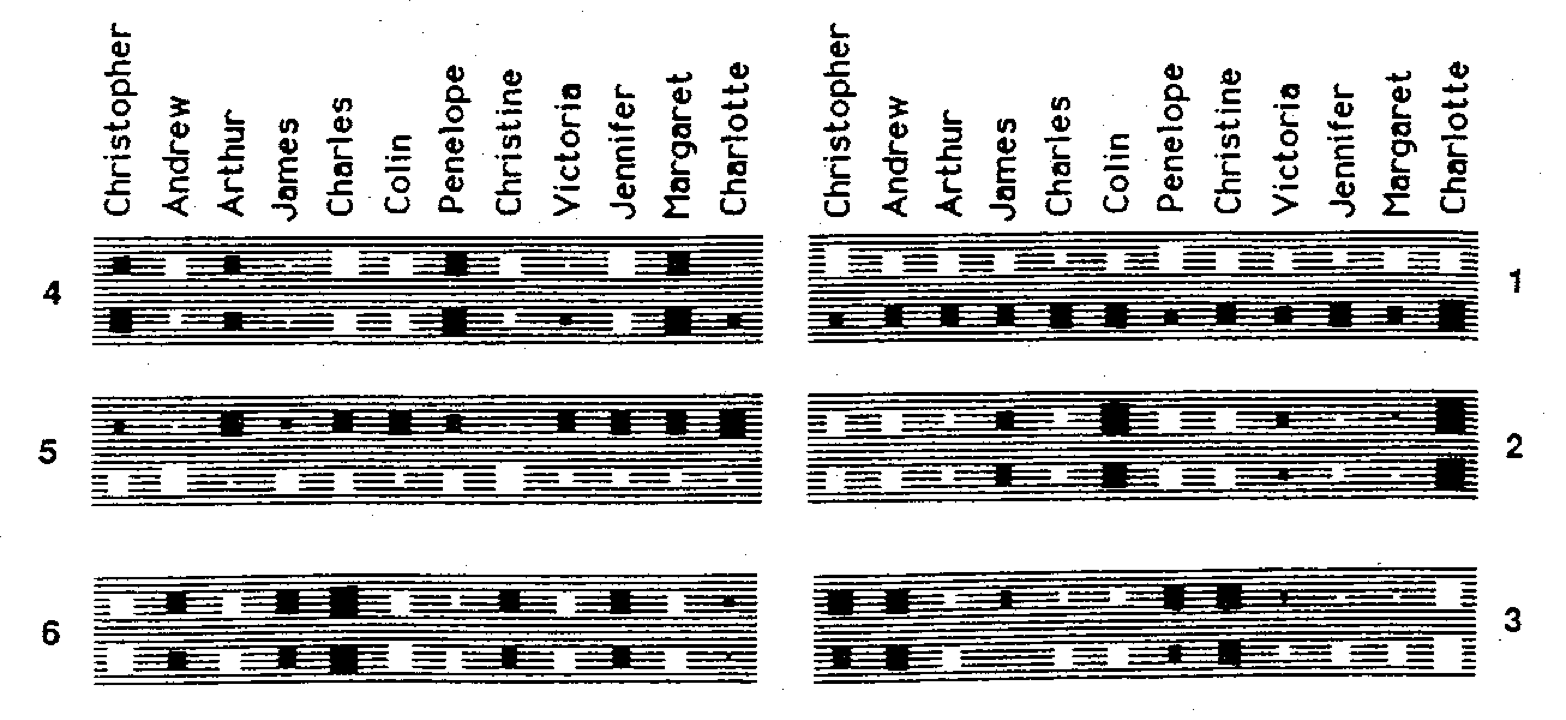
From Hilton (1986): White rectangles stand for positive weights, black for negative weights, and the area of a rectangle encodes the magnitude of its weight. The two isomorphic family trees are represented in two rows, aligned to equivalent members.
Hilton (1986) had his neural network learn two family trees and got interesting representations of family members as a by product. The trees were turned in to 104 propositions (person1, relation, person2) of which 100 were used for training. For each proposition, the neural network was given fillers of two first roles and asked to predict that of the third.
As of 2014, the paper was cited more than 500 times. The approach seems restricted regarding application and scalability.
Paccanaro & Hilton (2000)[6] proposed linear relational embedding which is somewhat simpler. Their later paper[7] extended the model to handle special cases where there is no answer or are multiple answers.
Proposition judgement

From Socher et al. 2013
Relation predicting
Bowman (2013)[8] employed a neural network with one hidden layer and one softmax layer to predict the relation (one of entailment, reverse entailment, equivalent, alternation, negation, cover, and independent) between two phrases.
Probabilistic inference informed by distributional similarity
Beltagy et al. (2013)[9] performed textual entailment recognization and semantic textual similarity by casting them as probabilistic entailment in Markov logic. For example, the similarity between two sentences:
S1: A man is slicing a cucumber.
S2: A man is slicing a zucchini.
is judged as judged as the average degree of mutual entailment ( and ). Strictly speaking, S1 does not entail S2 and vice versa. The authors fixed this by adding the rule cucumber(x)→zucchini(x) | wt(cuc., zuc.) which literally means "if something is a cucumber, it is also a zucchini" (with inference cost=wt(...)). wt(.) is a function of the cosine similarity between two words.


{kind=link}
{kind=link}
References
- ↑ Hinton, G. E. (1986, August). Learning distributed representations of concepts. In Proceedings of the eighth annual conference of the cognitive science society (Vol. 1, p. 12).
- ↑ Ultsch, A. (1994). The integration of neural networks with symbolic knowledge processing. In New Approaches in Classification and Data Analysis (pp. 445-454). Springer Berlin Heidelberg.
- ↑ Ultsch, A., & Korus, D. (1995, November). Integration of neural networks with knowledge-based systems. In Neural Networks, 1995. Proceedings., IEEE International Conference on (Vol. 4, pp. 1828-1833). IEEE.
- ↑ Socher, R., Chen, D., Manning, C. D., & Ng, A. (2013). Reasoning with neural tensor networks for knowledge base completion. In Advances in Neural Information Processing Systems (pp. 926-934).
- ↑ Rocktäschel, T., Bosnjak, M., Singh, S., & Riedel, S. Low-Dimensional Embeddings of Logic. ACL 2014 Workshop on Semantic Parsing.
- ↑ Paccanaro, A., and Hinton, G.E. Learning Distributed Representations by Mapping Concepts and Relations into a Linear Space ICML-2000, Proceedings of the Seventeenth International Conference on Machine Learning, Langley P. (Ed.), 711-718, Stanford University, Morgan Kaufmann Publishers, San Francisco.
- ↑ Paccanaro, A., & Hinton, G. E. (2000). Extracting distributed representations of concepts and relations from positive and negative propositions. In Neural Networks, 2000. IJCNN 2000, Proceedings of the IEEE-INNS-ENNS International Joint Conference on (Vol. 2, pp. 259-264). IEEE.
- ↑ Bowman, S. R. (2013). Can recursive neural tensor networks learn logical reasoning?. arXiv preprint arXiv:1312.6192.
- ↑ Beltagy, I., Chau, C., Boleda, G., Garrette, D., & Erk, K. (2013). Montague Meets Markov : Deep Semantics with Probabilistic Logical Form. Proceedings of the Second Joint Conference on Lexical and Computational Semantics (*Sem-2013), 11–21.